|
My name is Peng-Tao Jiang (姜鹏涛). Currently, I am a lead researcher in vivo BlueImage Lab. Before that, I was a post-doc researcher at Zhejiang University, working with Prof. Chunhua Shen. I received my PhD from Nankai University, advised by Prof. Ming-Ming Cheng. I have also completed internships at SenseTime and Tencent YouTu. My recent research interests mainly focus on the following topics: Email / CV / Google Scholar / Github |

|
|
[21.04,2026]: We release our new work SmartPhotoCrafter, which redefines photo editing by eliminating the need for explicit human instructions. Instead of relying on users to describe desired adjustments, it autonomously understands image quality deficiencies, reasons about the improvement strategies, and generates stunning, photo-realistic results—all in one tightly coupled process. [05.04,2026]: I am serving as an external member and advisor for the AI4X team, which is led by Xiaoqi Zhao. [01.04,2026]: Our SD-based DepthMaster has been accepted by TCSVT. Congrats to Ziyang. [20.02,2026]: [Call for papers] We are holding the 2nd international workshop on vision intelligence for real-world challenges at CVPR2026. [20.02,2026]: Four papers have been accepted by CVPR 2026. [21.11,2025]: Four papers have been accepted by ICLR 2026. [21.11,2025]: Two papers have been accepted by AAAI 2026 ORAL. [21.11,2025]: One paper has been accepted by TCSVT. [08.11,2025]: Two oral papers have been accepted by AAAI 2026. [08.24,2025]: Three papers have been accepted by NeurIPS 2025. [08.24,2025]: One paper has been accepted by TPAMI. [06.26,2025]: Three papers have been accepted by ICCV 2025. |
|
We are looking for self-motivated interns, working on the following topics:
|
|
* denotes equal contributions, # denotes corresponding authors. |
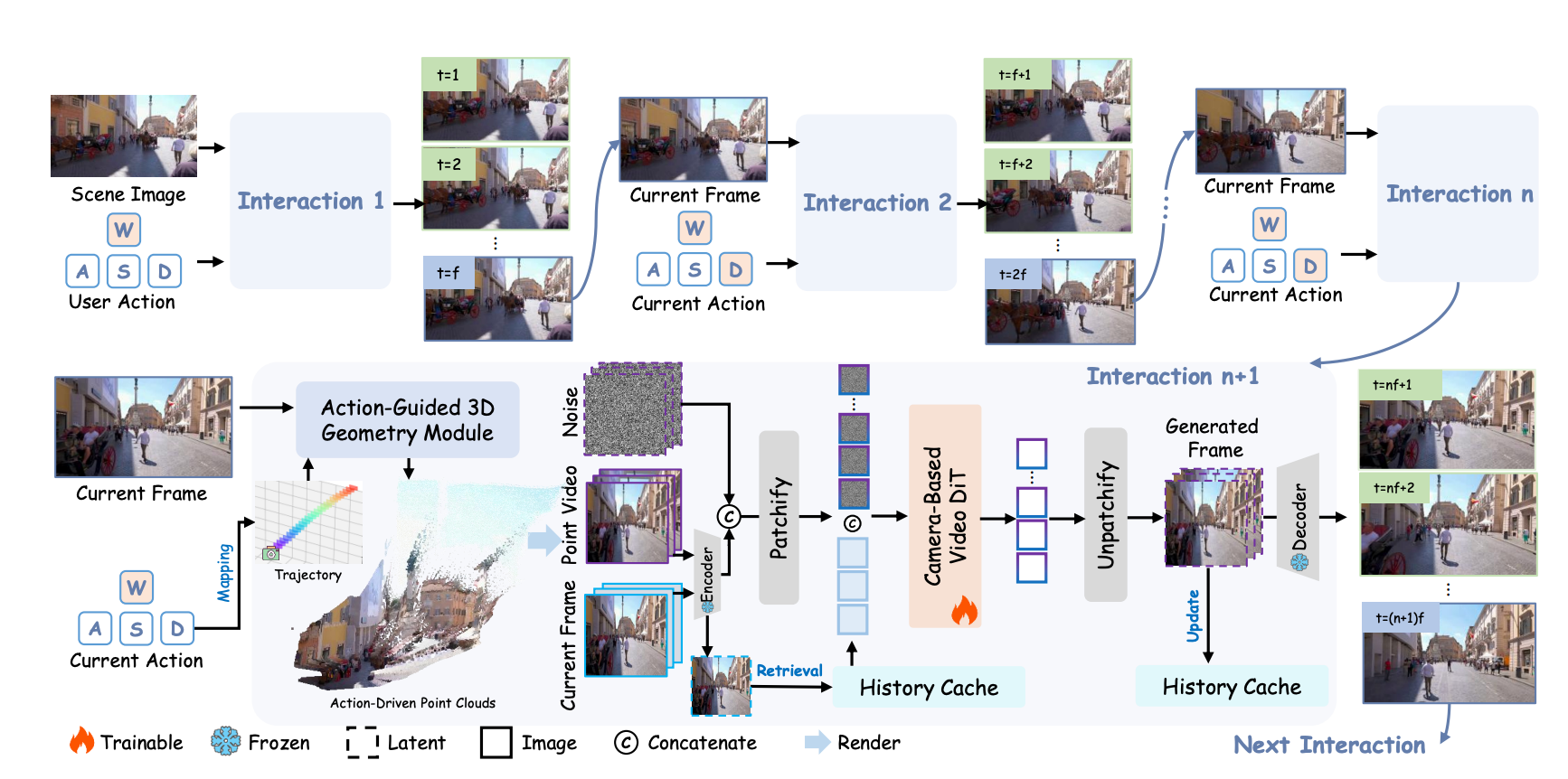 |
Guangyuan Li, Bo Li, Jinwei Chen, Xiaobin Hu, Lei Zhao#, Peng-Tao Jiang# arxiv, 2026 paper /code /project |
 |
Qirui Yang, Yang Yang, Ying Zeng, Xiaobin Hu, Bo Li, Huanjing Yue, Jingyu Yang#, Peng-Tao Jiang# arxiv, 2025 paper /code /project |
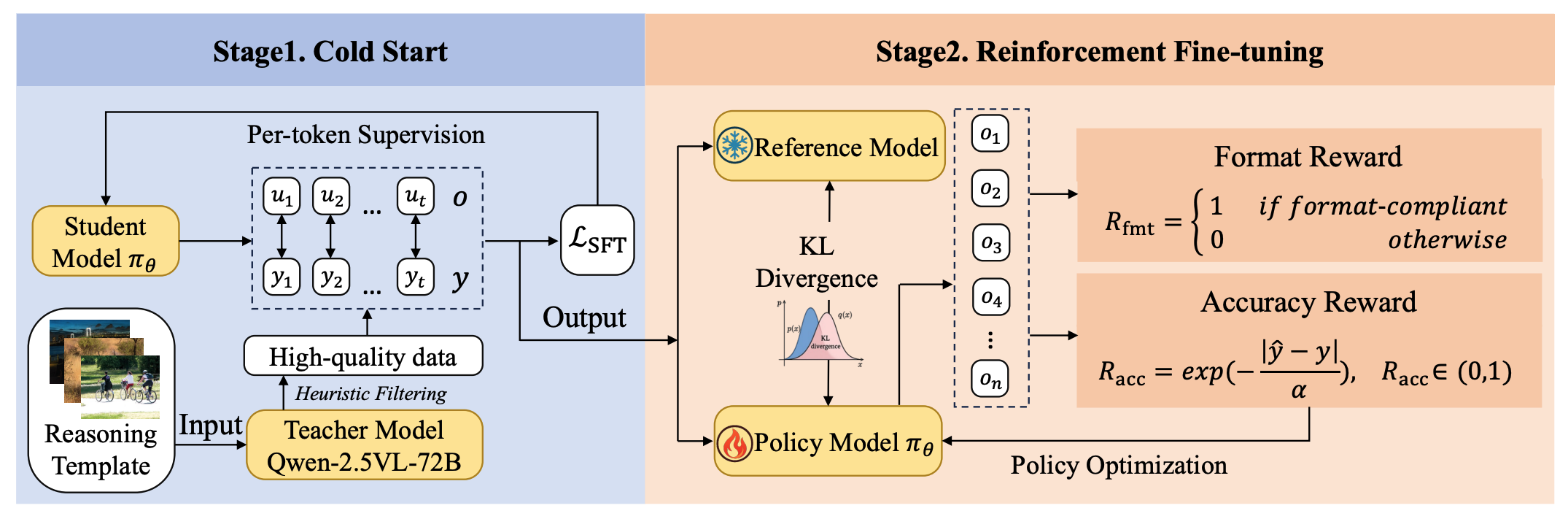 |
Zhuoxuan Cai, Jian Zhang, Xinbin Yuan, Peng-Tao Jiang, Wenxiang Chen, Bowen Tang, Lujian Yao, Qiyuan Wang, Jinwen Chen, Bo Li# arxiv, 2025 paper /code /project |
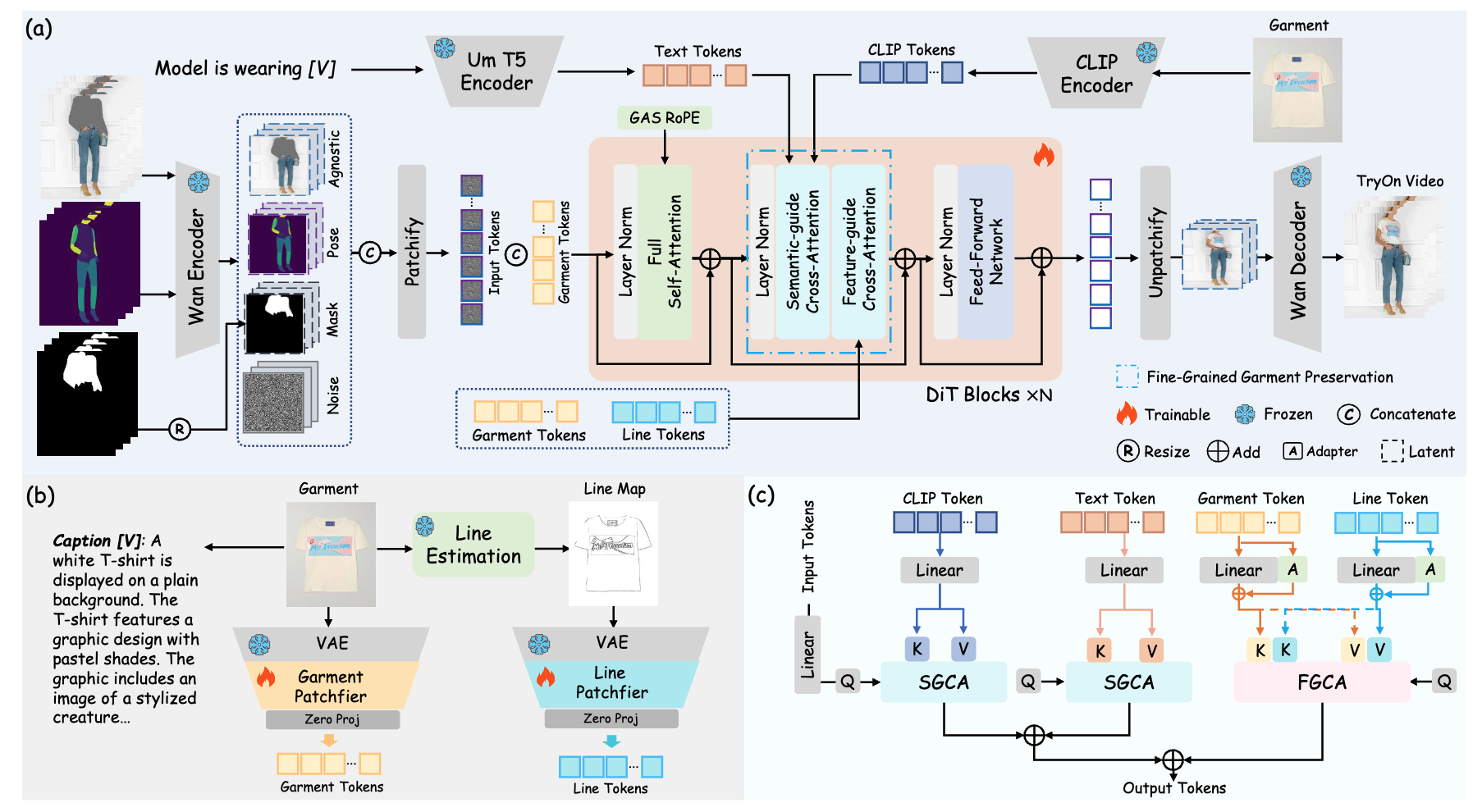 |
Guangyuan Li*, Siming Zheng*, Hao Zhang, Jinwei Chen, Junsheng Luan, Binkai Ou, Lei Zhao#, Bo Li, Peng-Tao Jiang# arxiv, 2025 paper /code /project |
 |
Ziyang Song*, Zerong Wang*, Bo Li, Hao Zhang, Ruijie Zhu, Li Liu, Peng-Tao Jiang#, Tianzhu Zhang# TCSVT, 2026 paper /code /project |
 |
Jiayang Gao, Tianyi Zheng, Jiayang Zou, Fengxiang Yang, Shice Liu, Luyao Fan, Zheyu Zhang, Hao Zhang, Jinwei Chen, Peng-Tao Jiang, Bo Li, Jia Wang ICLR, 2026 paper |
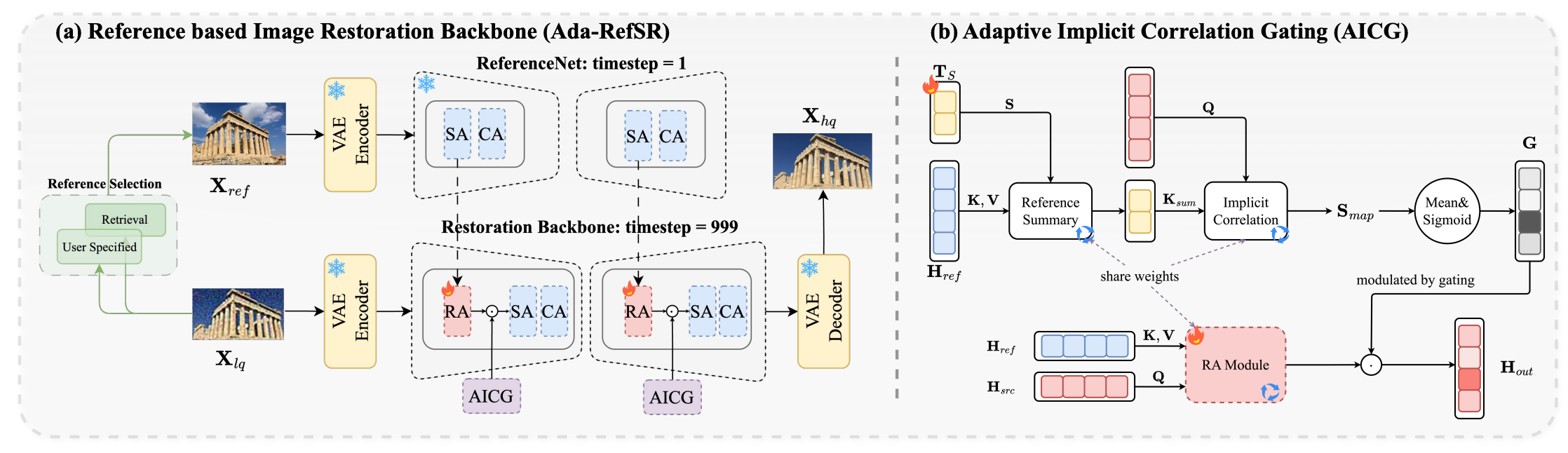 |
Yuan Wang, Yuhao Wan, Siming Zheng, Bo Li, Qibin Hou, Peng-Tao Jiang# ICLR, 2026 paper /code |
 |
Yang Yang*, Siming Zheng*, Jinwei Chen, Boxi Wu#, Xiaofei He, Deng Cai, Bo Li, Peng-Tao Jiang# ICLR, 2026 paper /code /project |
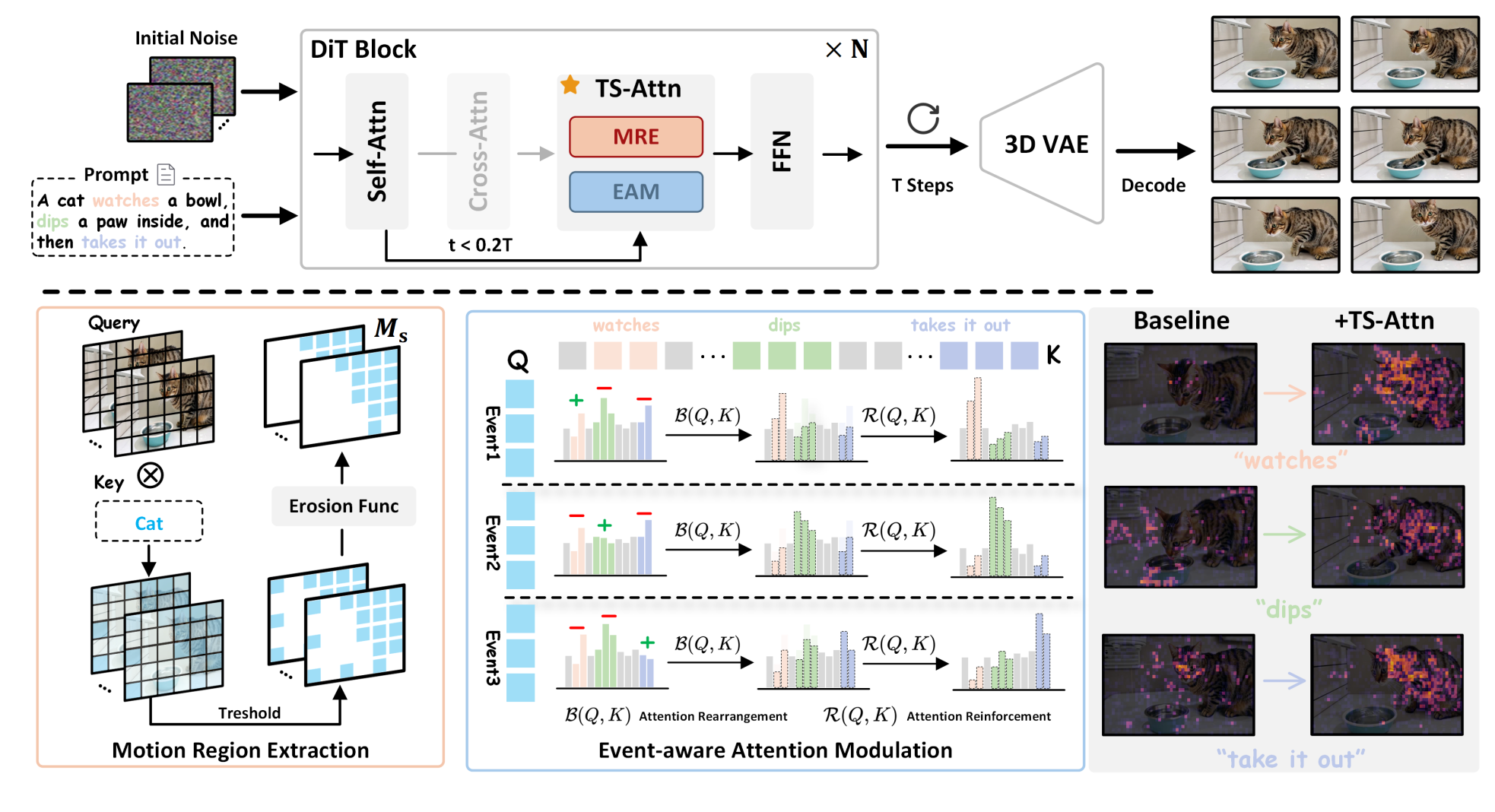 |
Hongyu Zhang, Yufan Deng, Zilin Pan, Peng-Tao Jiang, Bo Li, Qibin Hou, Zhen Dong, Zhiyang Dou, Daquan Zhou ICLR, 2026 paper /code |
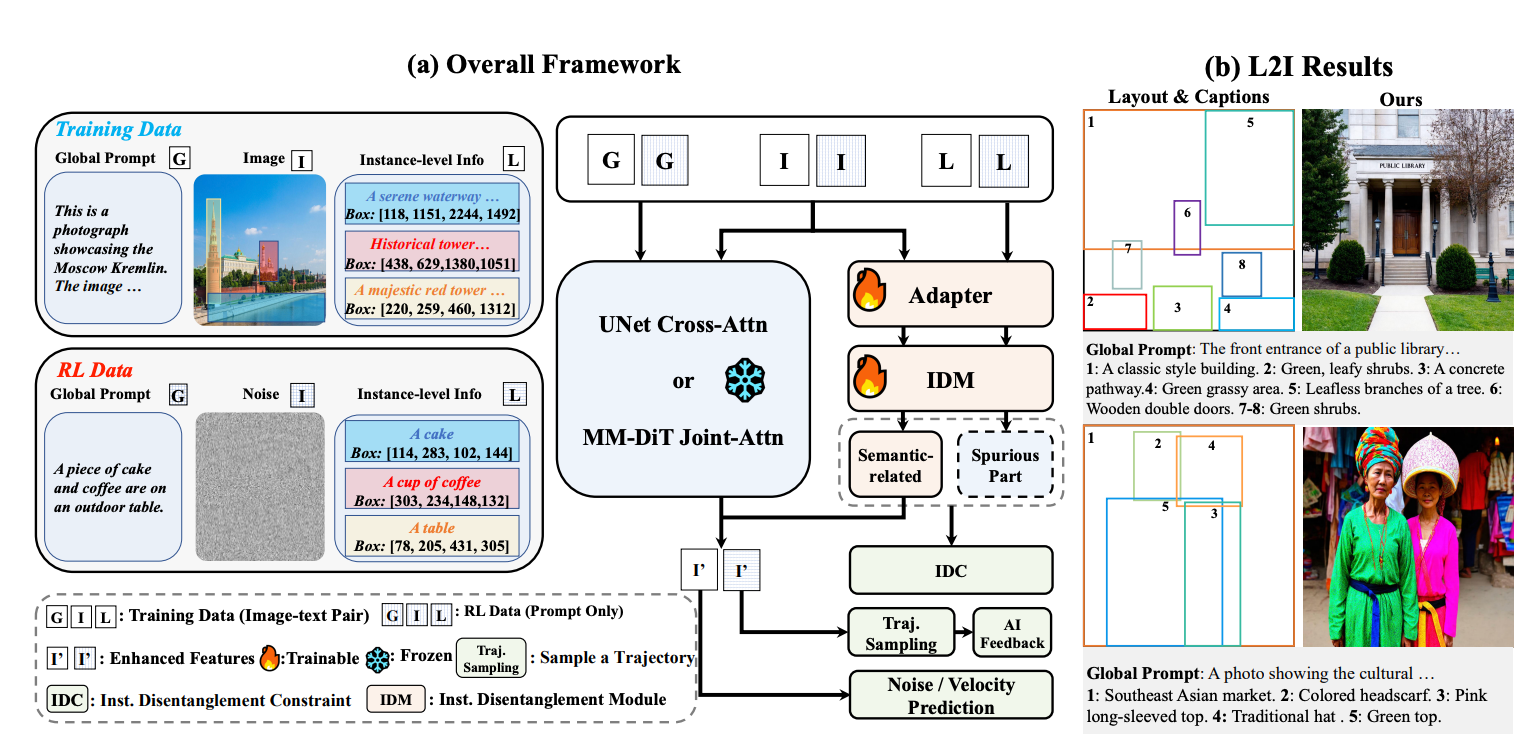 |
Fengxiang Yang, Tianyi Zheng, Bangjie Yin, Shice Liu, Peng-Tao Jiang, Jinwei Chen, Bo Li# ICLR, 2026 paper |
|
|
Yang Yang*, Siming Zheng*, Jinwei Chen, Boxi Wu#, Xiaofei He, Deng Cai, Bo Li, Peng-Tao Jiang# ICLR, 2026 paper /code /project |
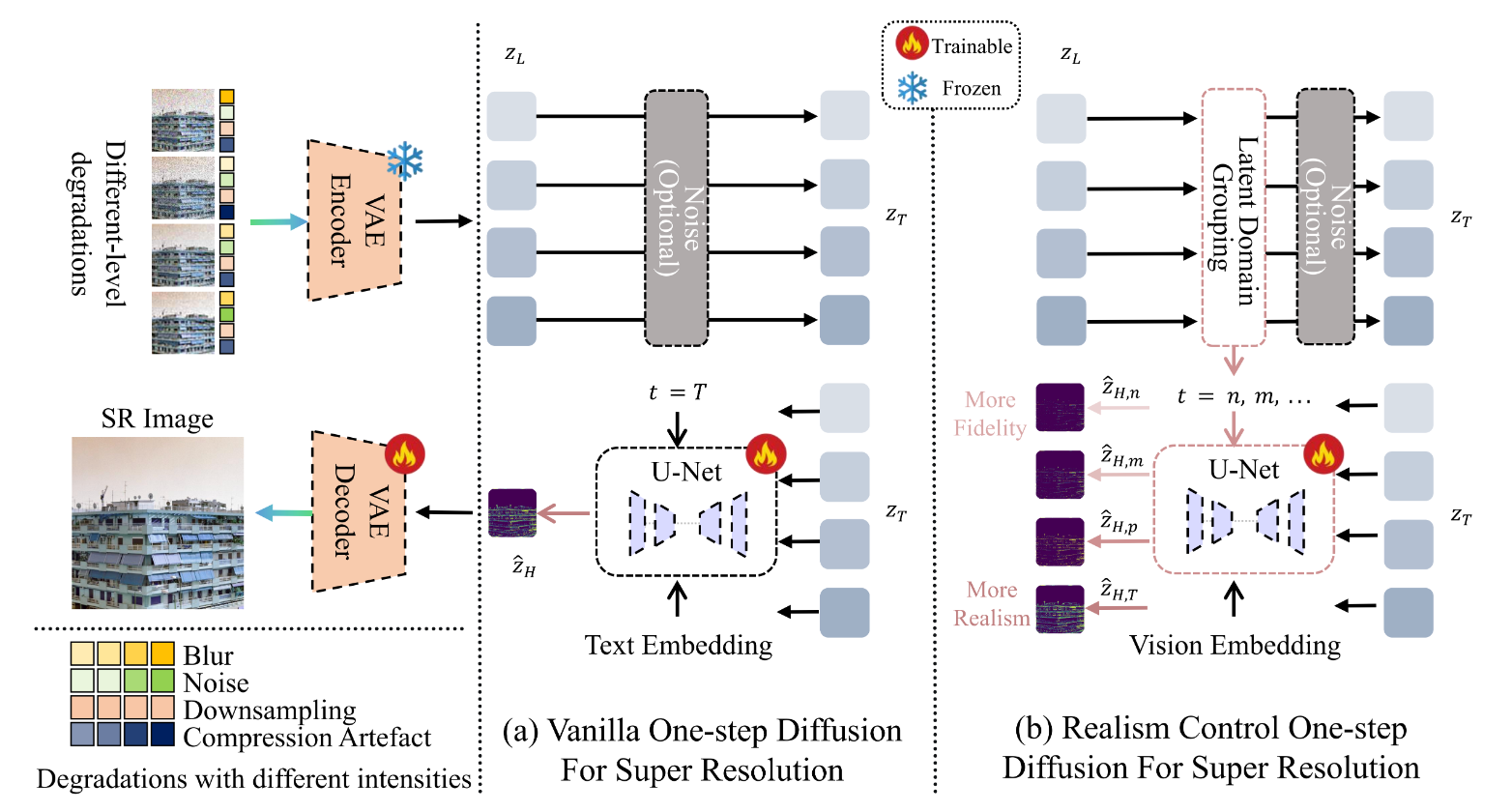 |
Zongliang Wu*, Siming Zheng*, Peng-Tao Jiang#, Xin Yuan# AAAI, 2026, ORAL paper /code /project |
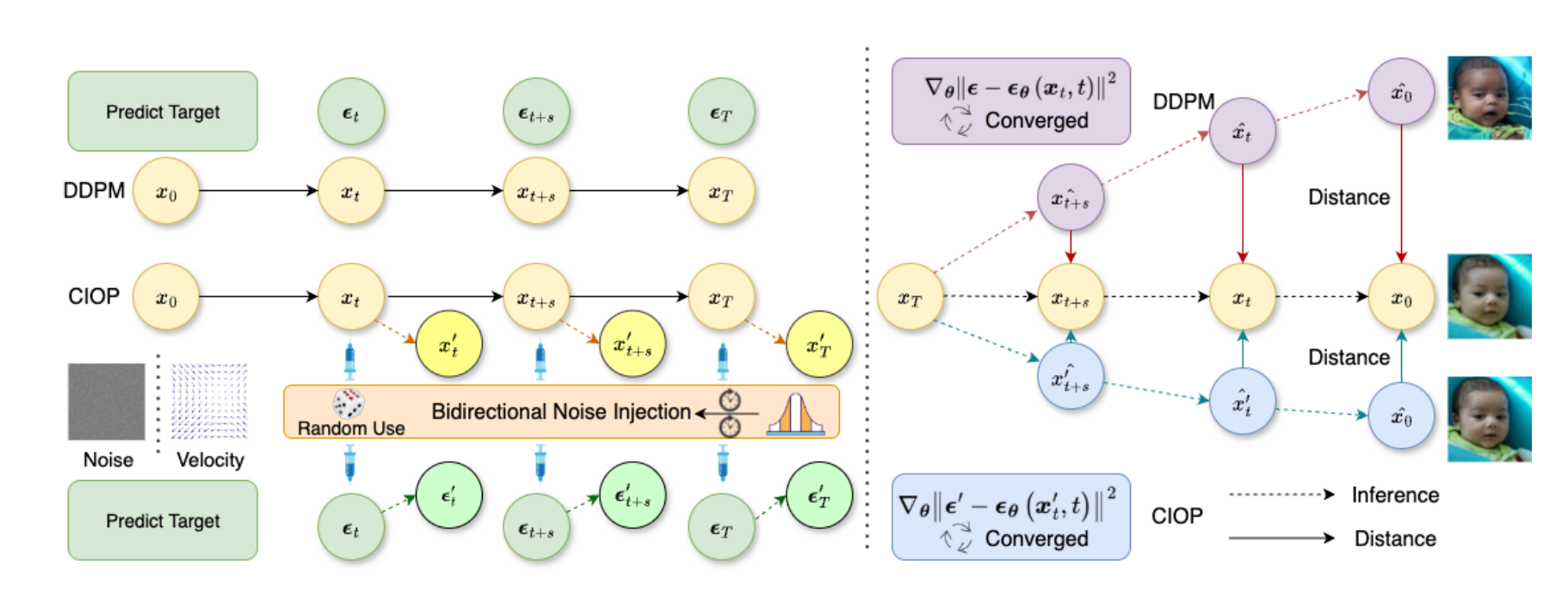 |
Tianyi Zheng, Tianyi_Zheng, Jiayang Gao, Peng-Tao Jiang, Fengxiang Yang, Ben Wan, Hao Zhang, Jinwei Chen, Jia Wang, Bo Li AAAI, 2026, ORAL paper |
 |
Ruihao Xia, Yu Liang, Peng-Tao Jiang#, Hao Zhang, Qianru Sun, Yang Tang#, Bo Li, Pan Zhou TCSVT, 2025 paper /code |
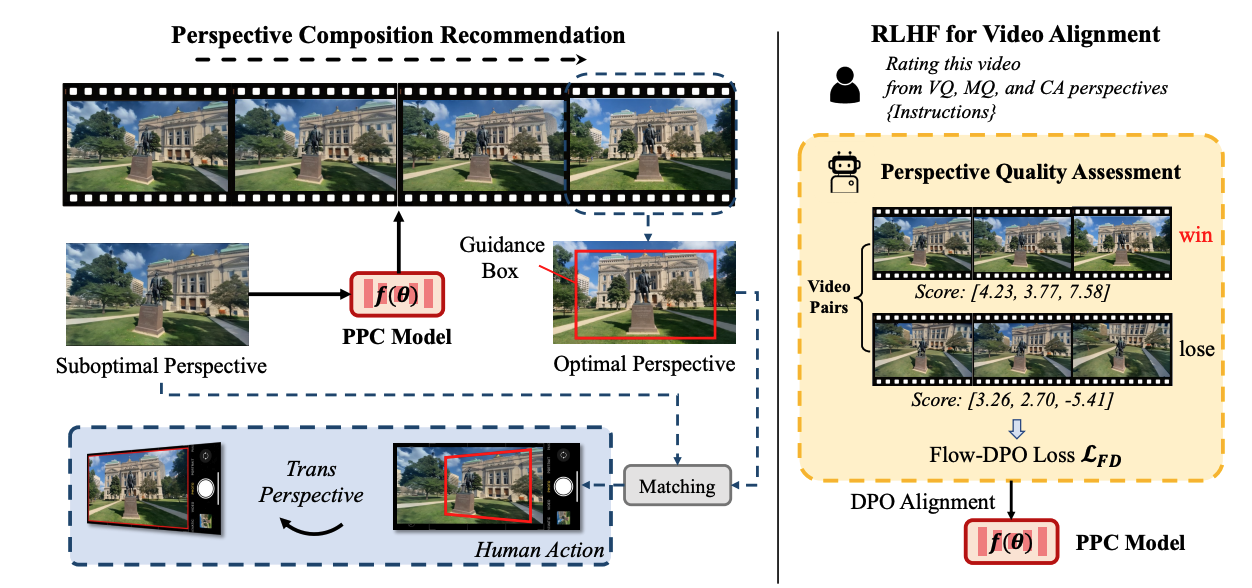 |
Lujian Yao*, Siming Zheng*, Xinbin Yuan, Zhuoxuan Cai, Pu Wu, Jinwei Chen, Bo Li, Peng-Tao Jiang# NeurIPS, 2025 paper /code /project |
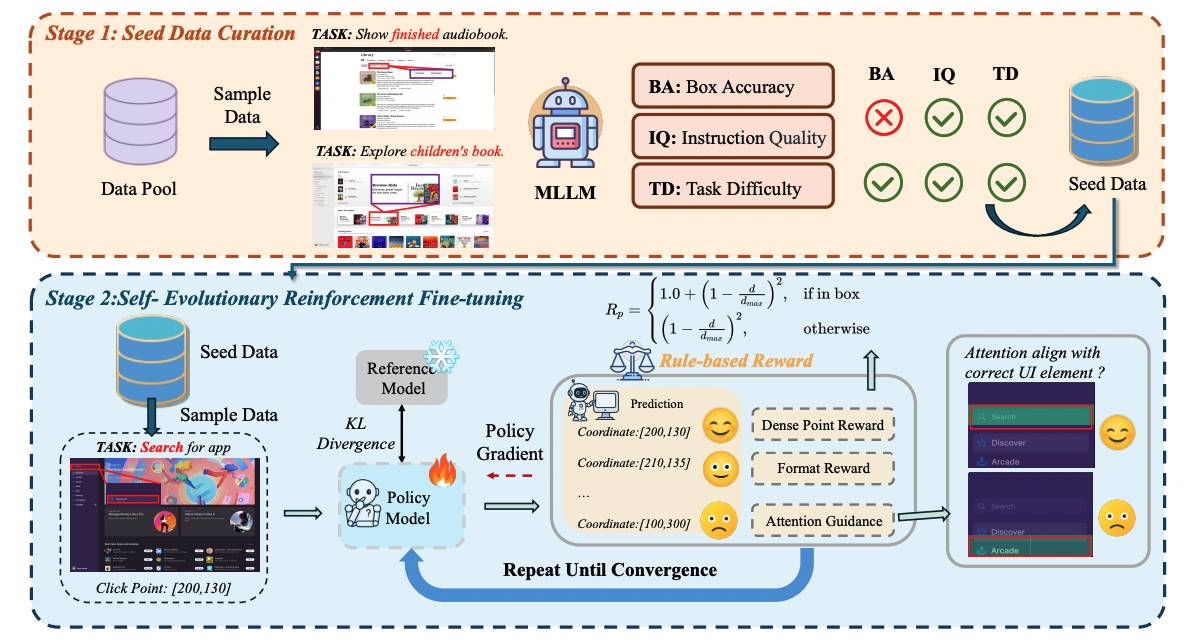 |
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, Bo Li NeurIPS, 2025 paper |
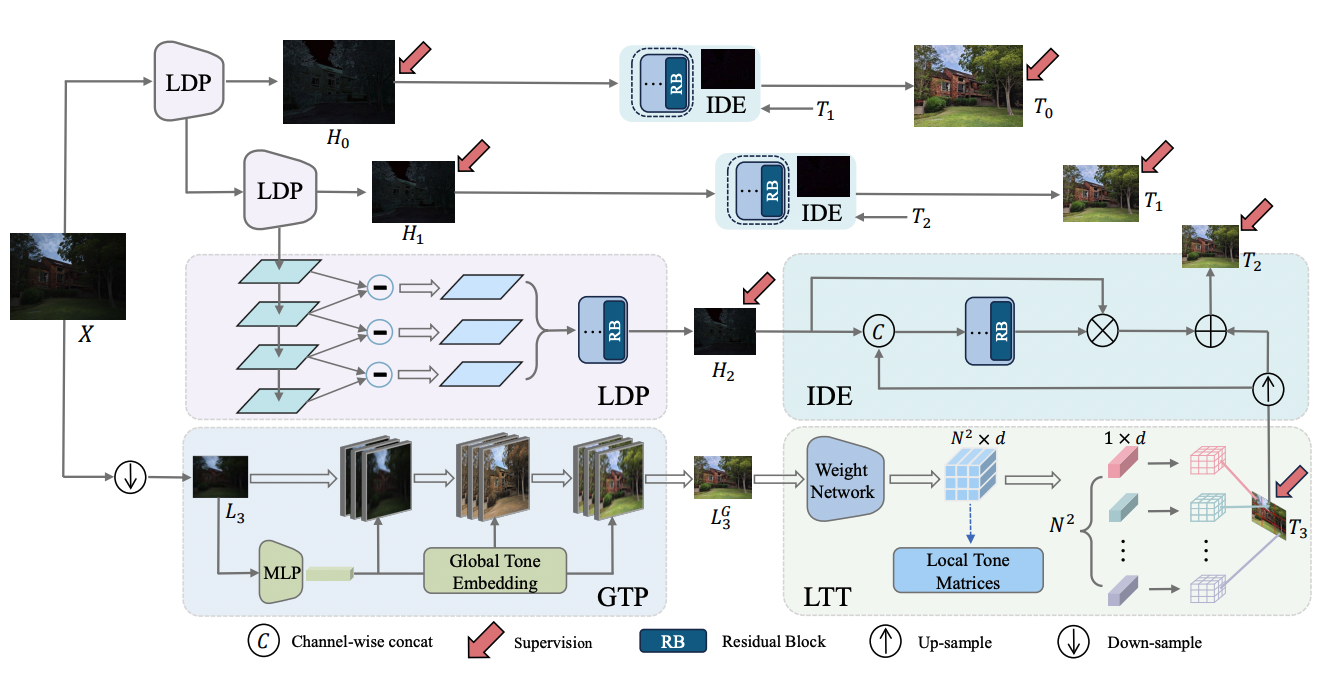 |
Qirui Yang, Yinbo Li, Peng-Tao Jiang, Qihua Cheng, Biting Yu, Yihao Liu, Huanjing Yue, Jingyu Yang NeurIPS, 2025 paper /demo |
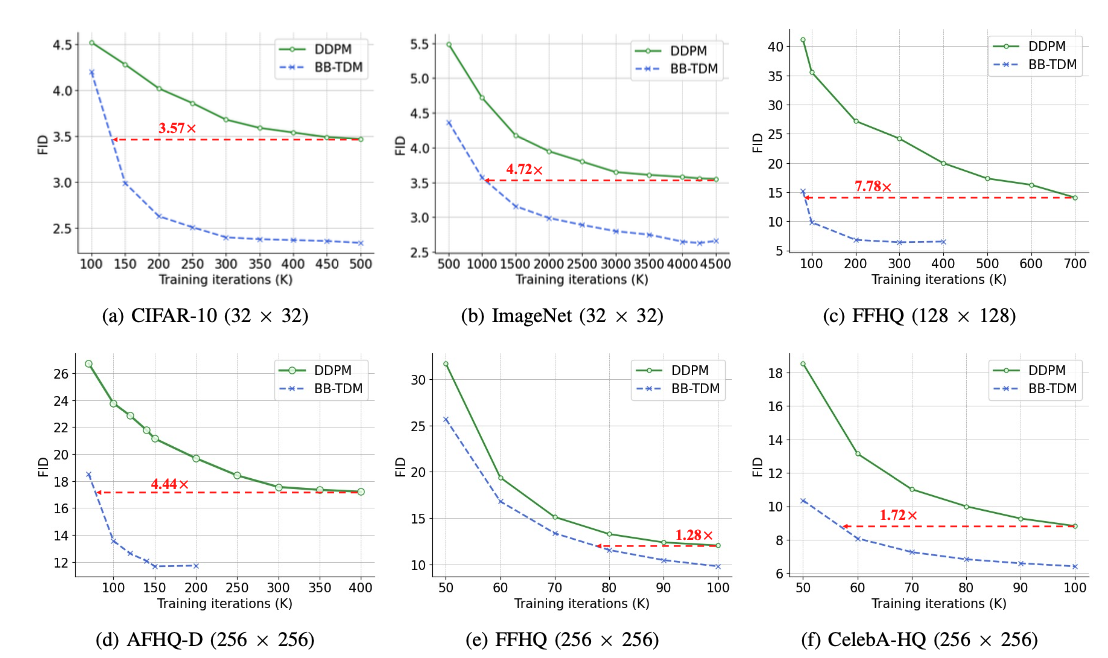 |
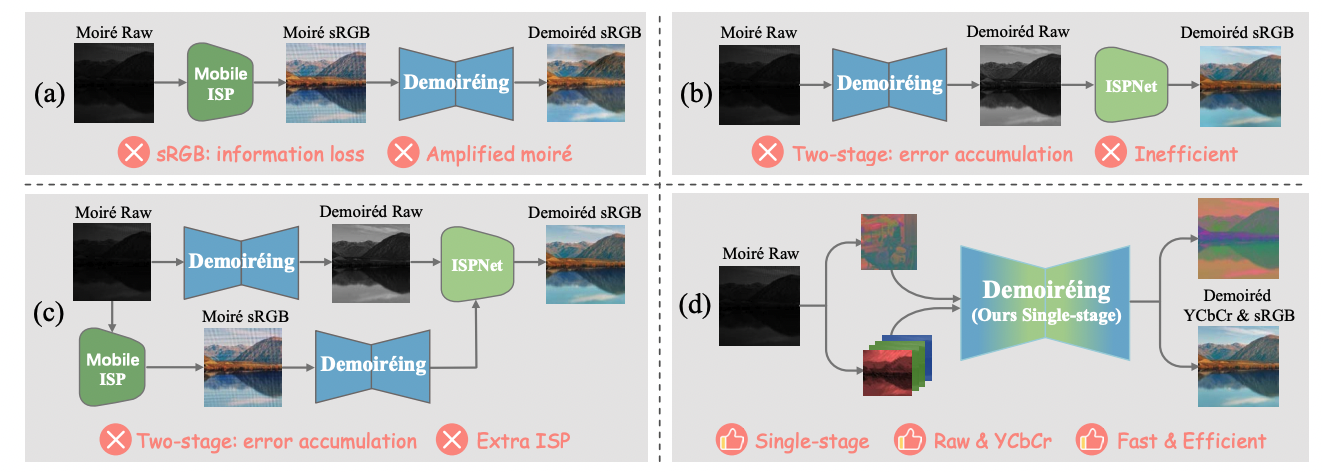
Tianyi Zheng, Jiayang Zou, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Jia Wang, Bo Li TPAMI, 2025 paper |
 |
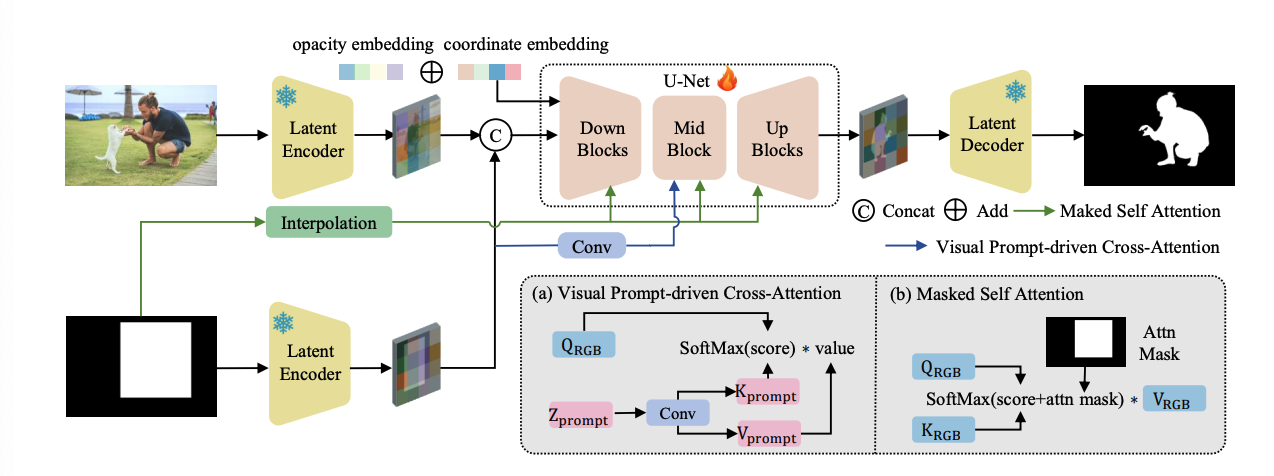
Qirui Yang, Fangpu Zhang, Yeying Jin, Qihua Cheng, Peng-Tao Jiang, Huanjing Yue, Jingyu Yang ACM MM, 2025 paper / demo |
 |
Longfei Huang, Yu Liang, Hao Zhang, Jinwei Chen, Wei Dong, Lunde Chen, Wanyu Liu, Bo Li, Peng-Tao Jiang# ICCV, 2025 paper / code |
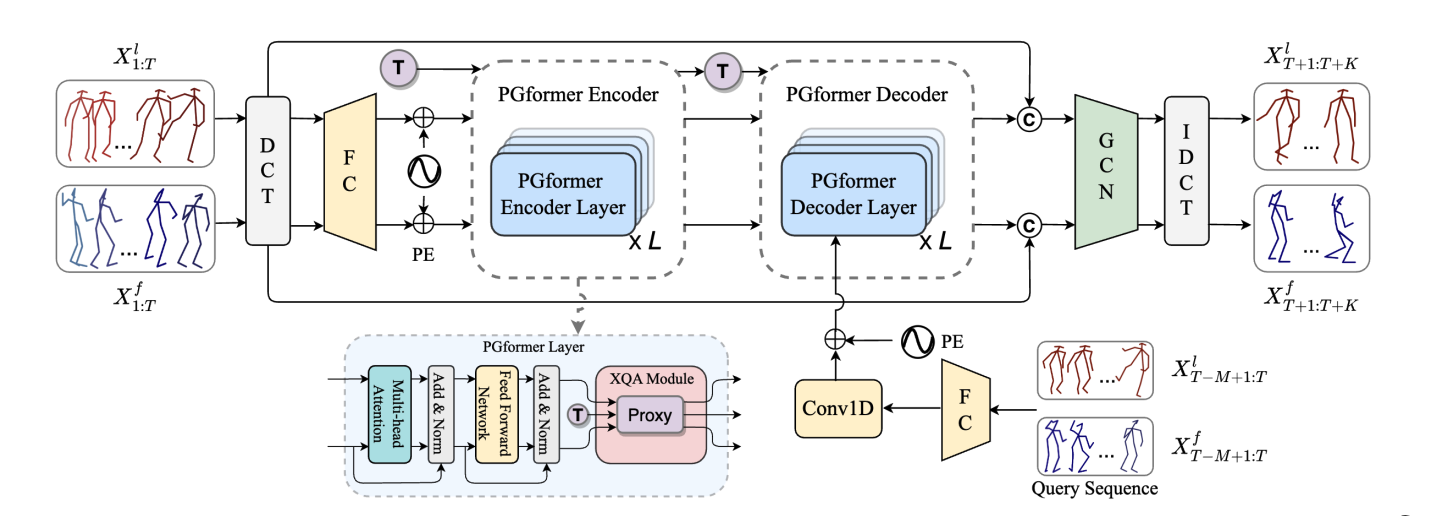 |
Yanwen Fang, Jintai Chen, Peng-Tao Jiang, Chao Li, Yifeng Geng, Eddy K. F. Lam, Guodong Li ICCV, 2025 paper / code |
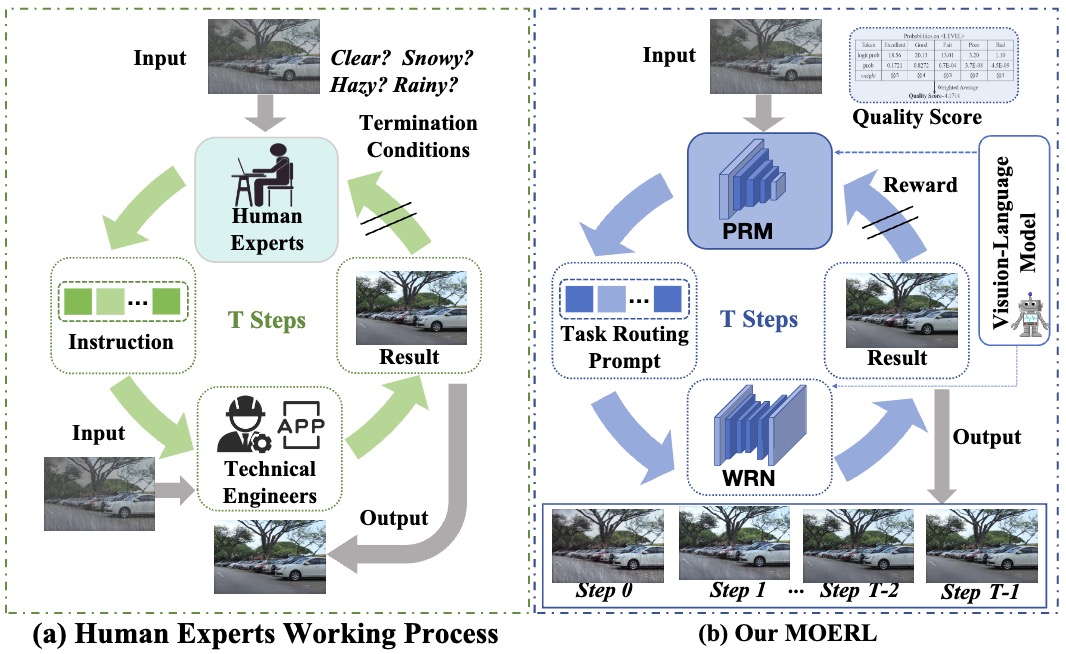 |
Tao Wang, Peiwen Xia, Bo Li, Peng-Tao Jiang, Zhe Kong, Kaihao Zhang, Tong Lu, Wenhan Luo ICCV, 2025 paper / code |
 |
Qirui Yang*, Peng-Tao Jiang*#, Hao Zhang, Jinwei Chen, Bo Li, Huanjing Yue, Jingyu Yang# ICML, 2025 paper / demo |
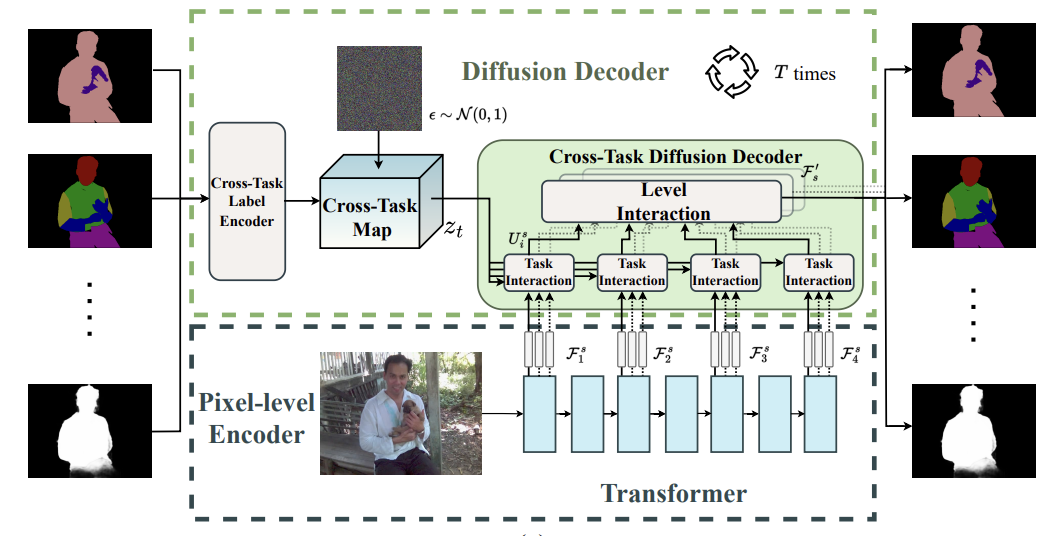 |
Yuqi Yang*, Peng-Tao Jiang*, Qibin Hou#, Hao Zhang, Jinwei Chen, Bo Li ICLR, 2025 paper / code |
 |
Qian Yu*, Peng-Tao Jiang*#, Hao Zhang, Jinwei Chen, Bo Li, Lihe Zhang#, Huchuan Lu ICLR, 2025 paper / code |
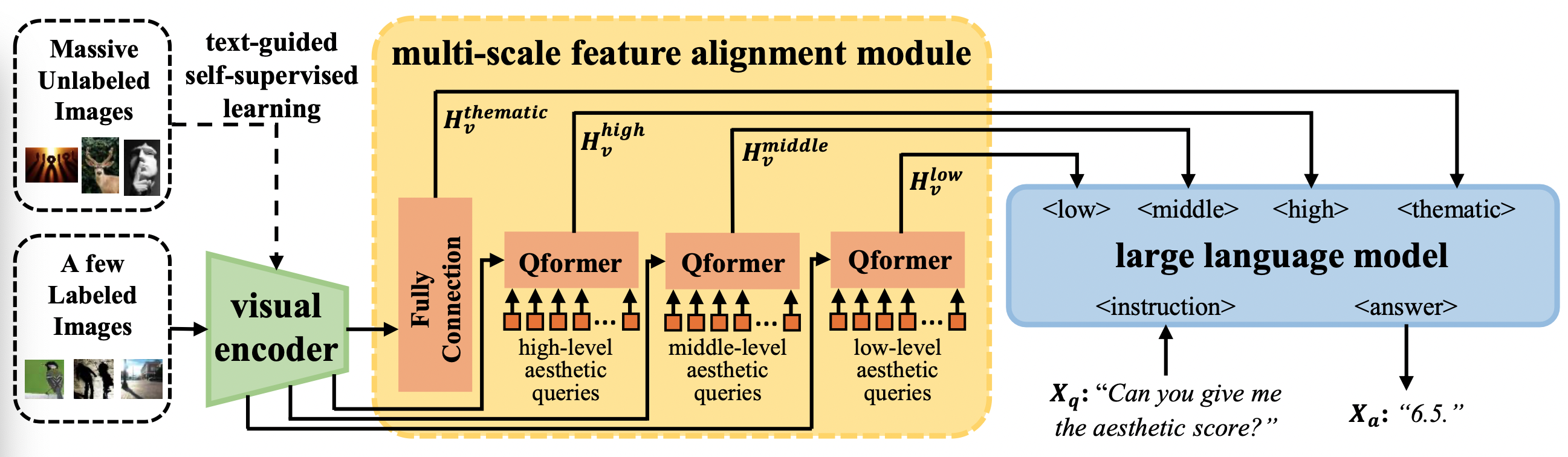 |
Yuti Liu, Shice Liu, Junyuan Gao, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Bo Li# AAAI, 2025 paper |
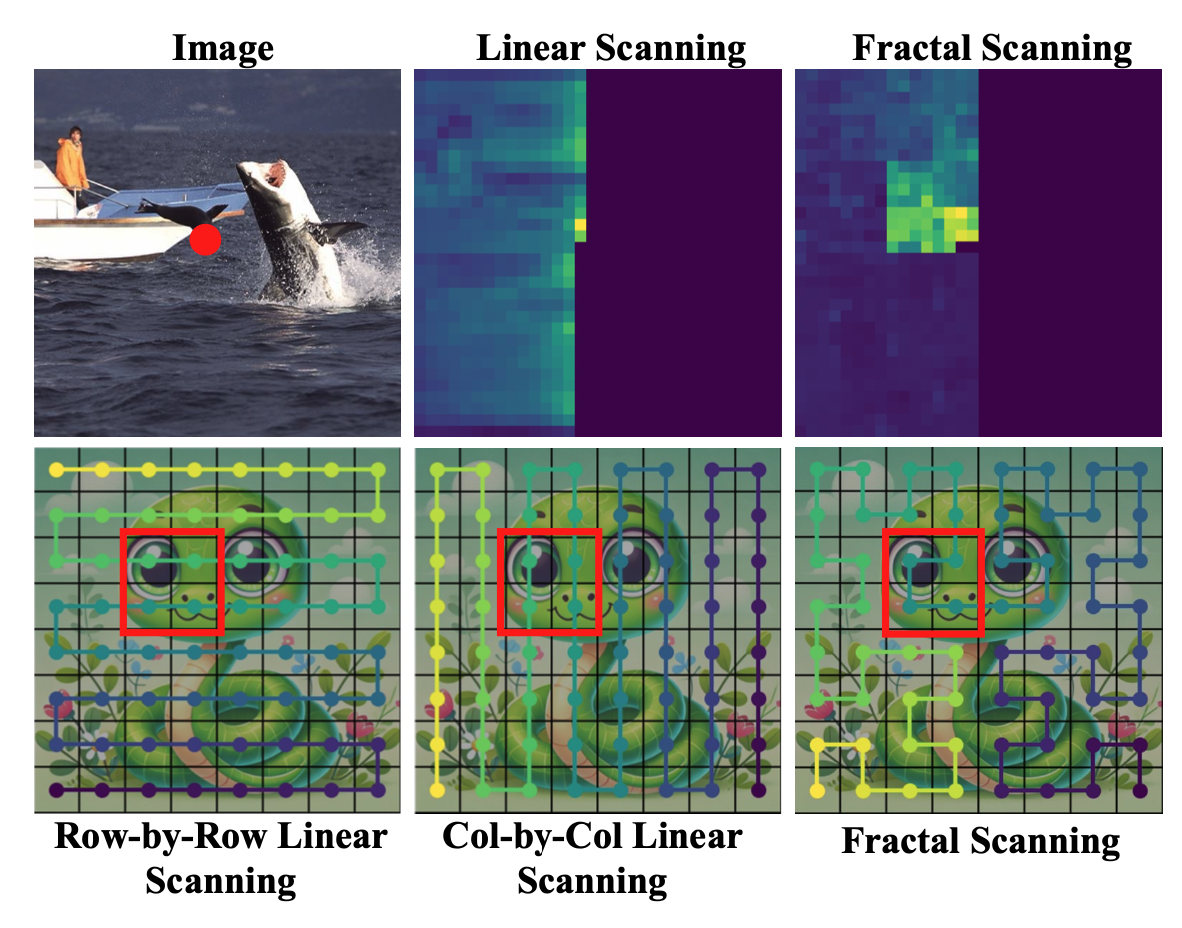 |
Haoke Xiao*, Lv Tang*, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Bo Li# AAAI, 2025, ORAL paper |
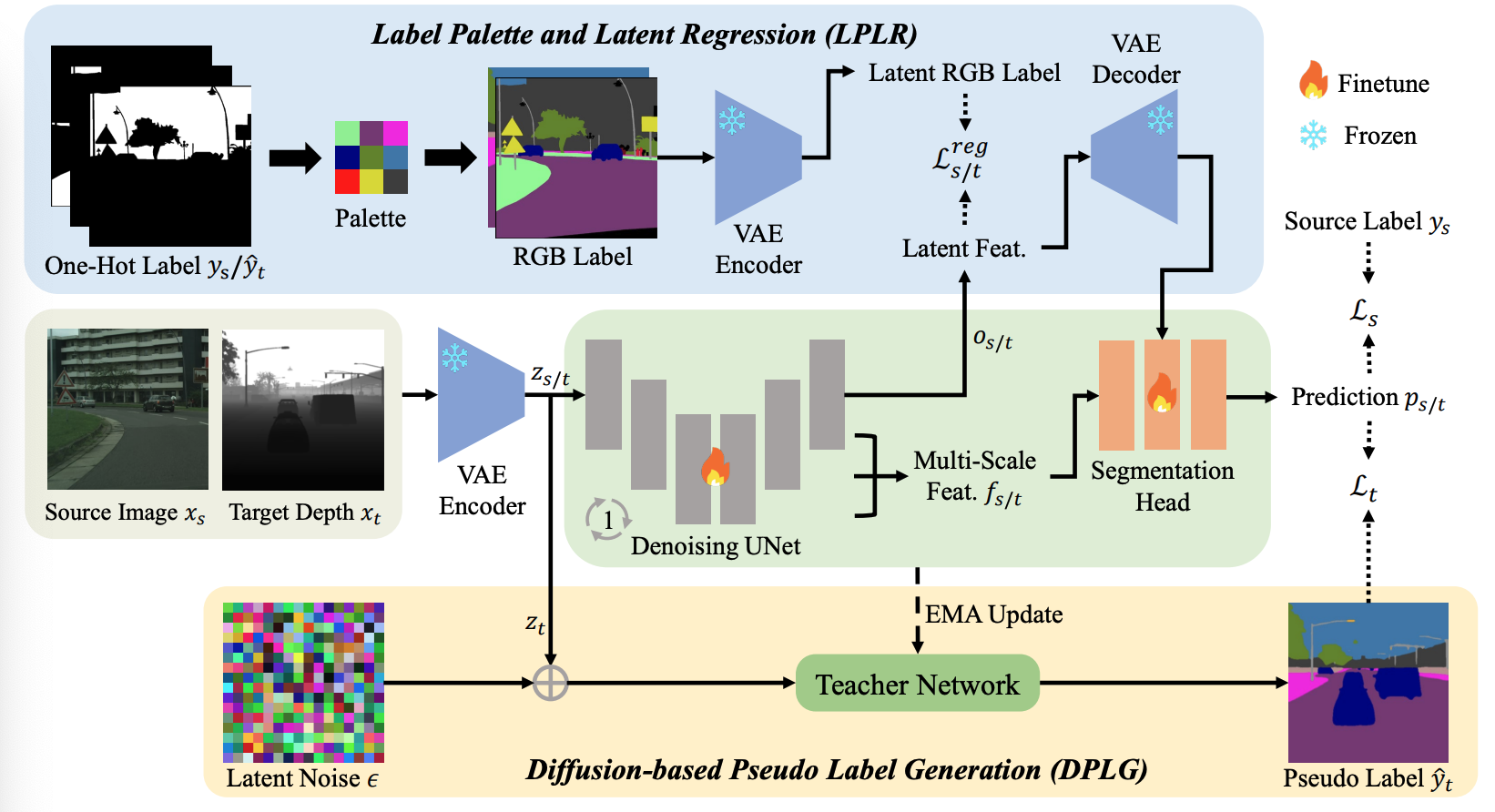 |
Ruihao Xia, Yu Liang, Peng-Tao Jiang, Hao Zhang, Bo Li#, Yang Tang#, Pan Zhou NeurIPS, 2024 paper / code |
 |
Lv Tang, Peng-Tao Jiang, Zhihao Shen, Hao Zhang, Jinwei Chen, Bo Li ACM MM, 2024 paper / code |
 |
Tianyi Zheng, Cong Geng, Peng-Tao Jiang, Ben Wan, Hao Zhang, Jinwei Chen, Jia Wang#, Bo Li# ACM MM, 2024 paper |
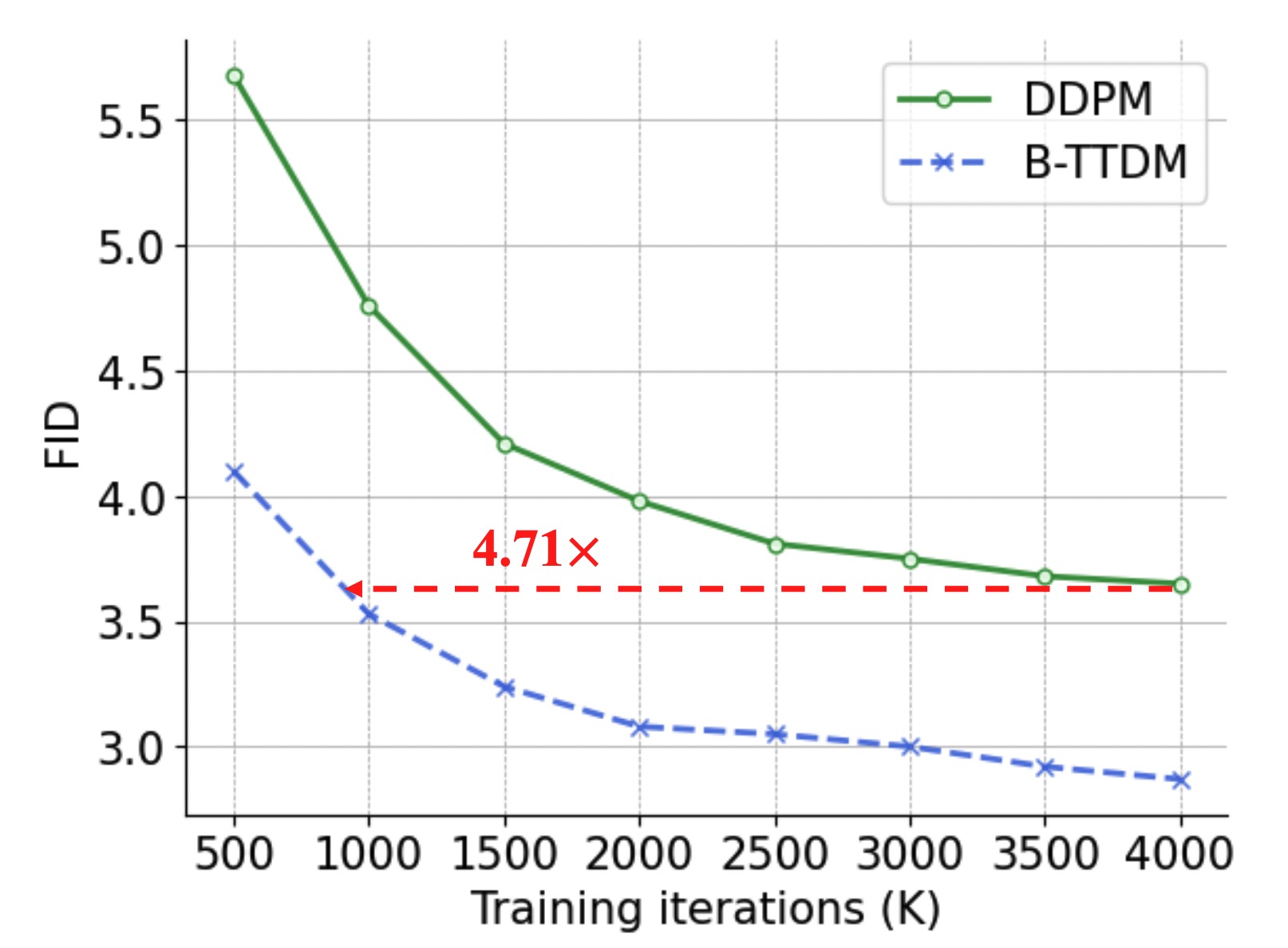 |
Tianyi Zheng, Peng-Tao Jiang, Ben Wan, Hao Zhang, Jinwei Chen, Jia Wang#, Bo Li# ACM MM, 2024 paper |
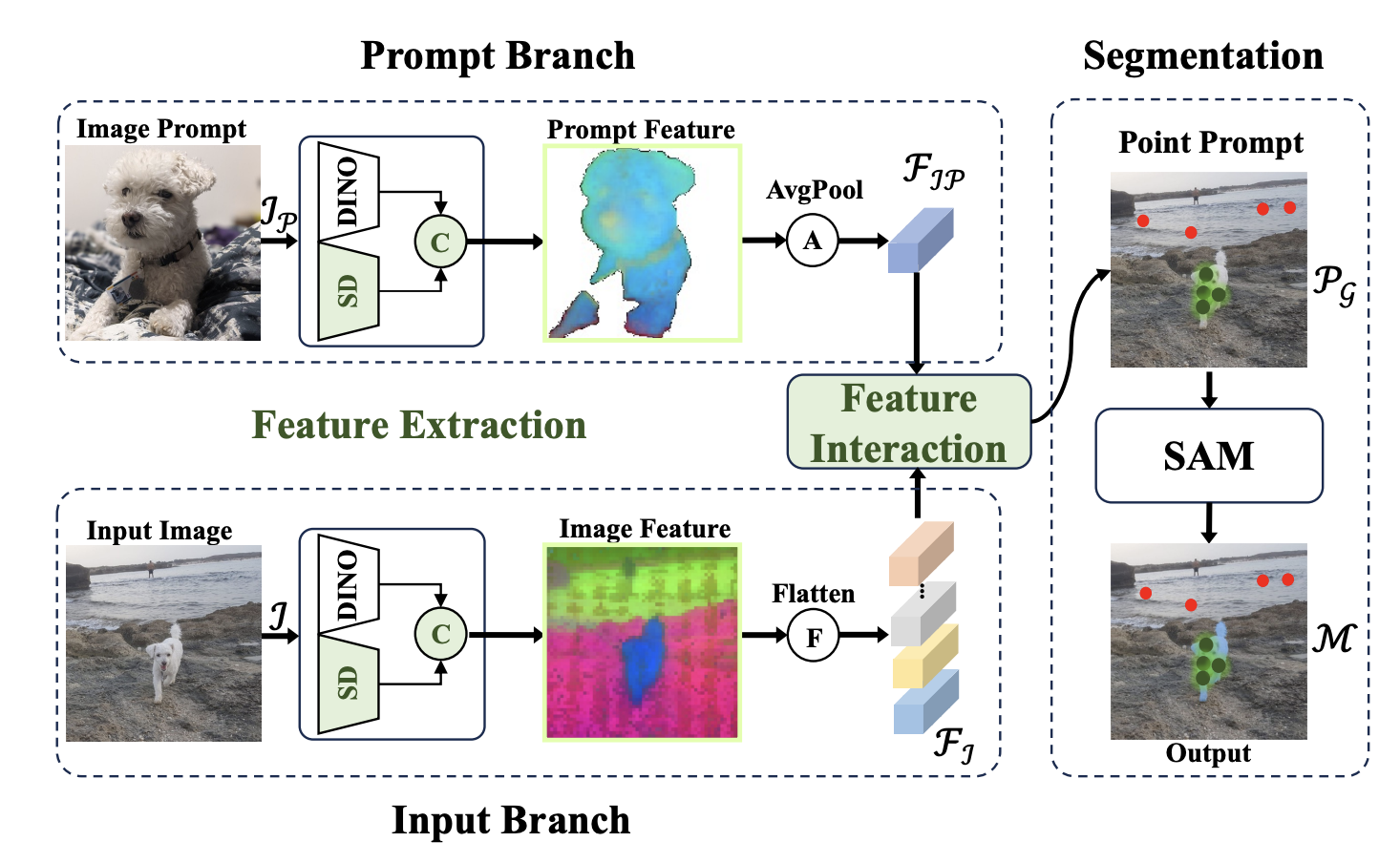 |
Lv Tang*, Peng-Tao Jiang*, Haoke Xiao*, Bo Li# IJCV, 2024 paper |
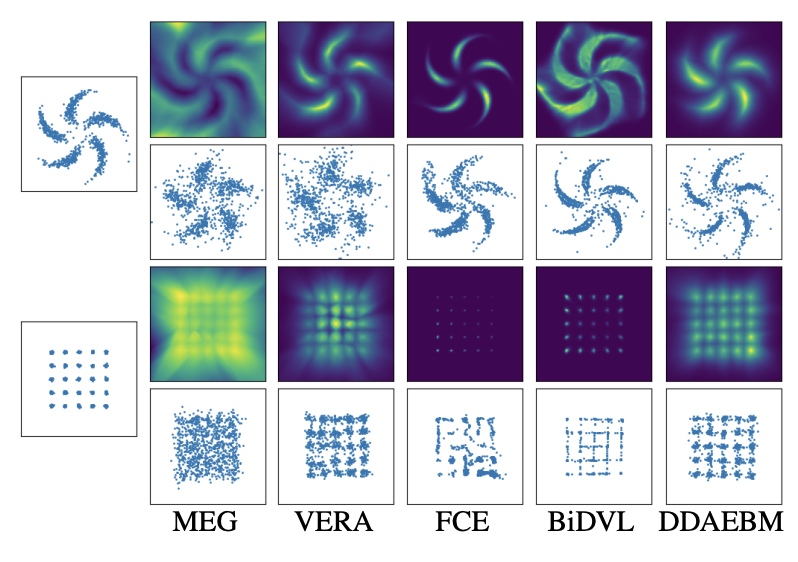 |
Cong Geng, Tian Han, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, Søren Hauberg, Bo Li ICML, 2024 paper |
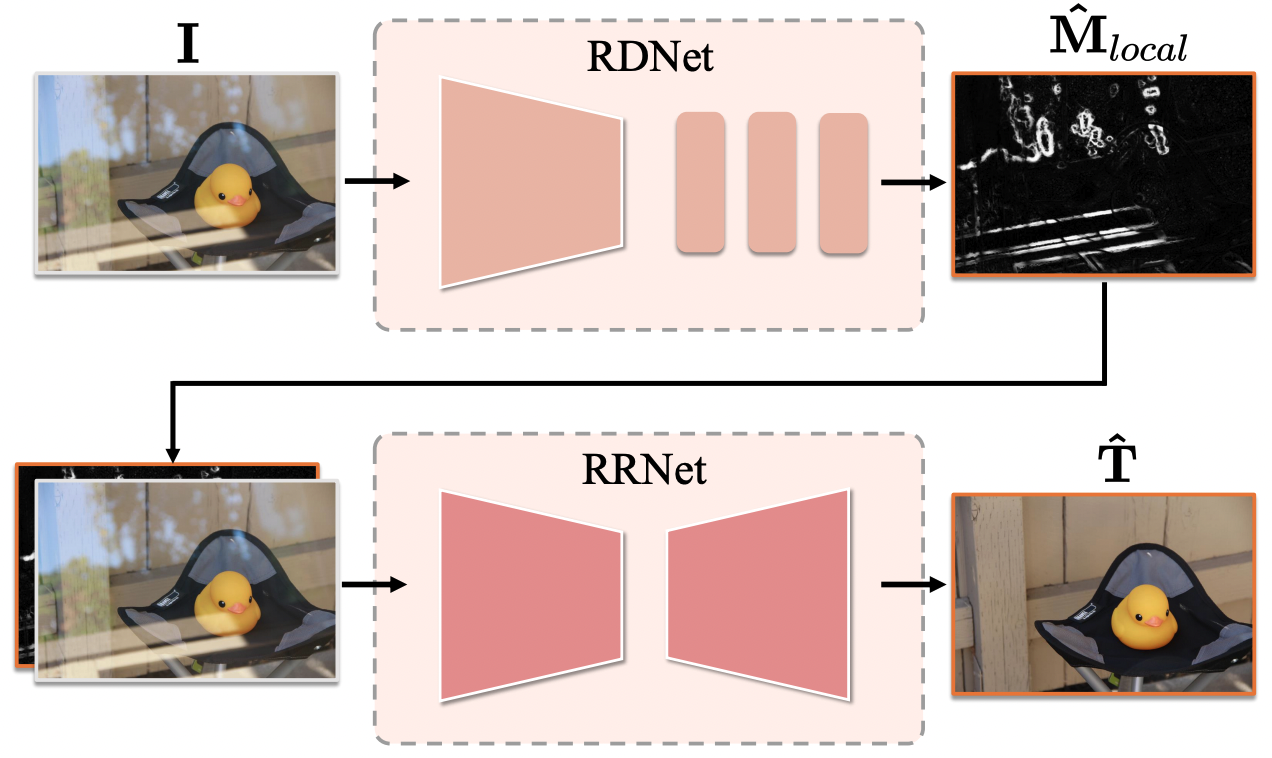 |
Yurui Zhu, Xueyang Fu, Peng-Tao Jiang, Hao Zhang, Qibin Sun, Jinwei Chen, Zheng-Jun Zha, Bo Li CVPR, 2024 paper /code |
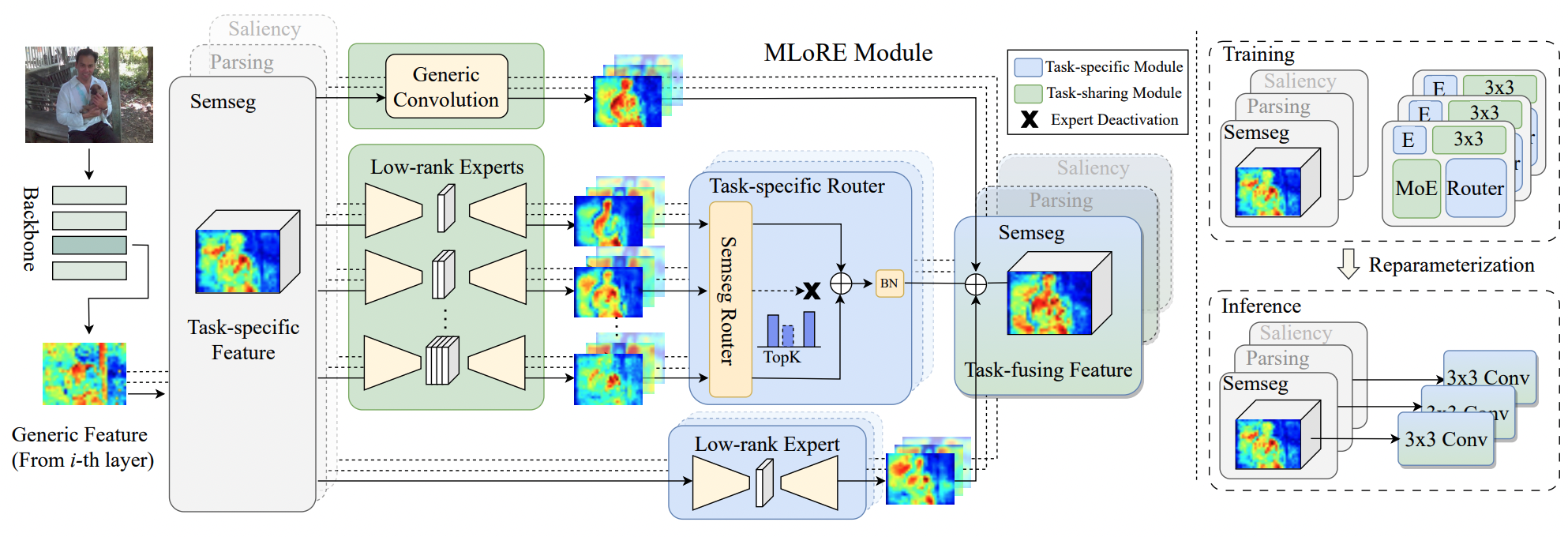 |
Yuqi Yang*, Peng-Tao Jiang*, Qibin Hou, Hao Zhang, Jinwei Chen, Bo Li CVPR, 2024 paper /code |
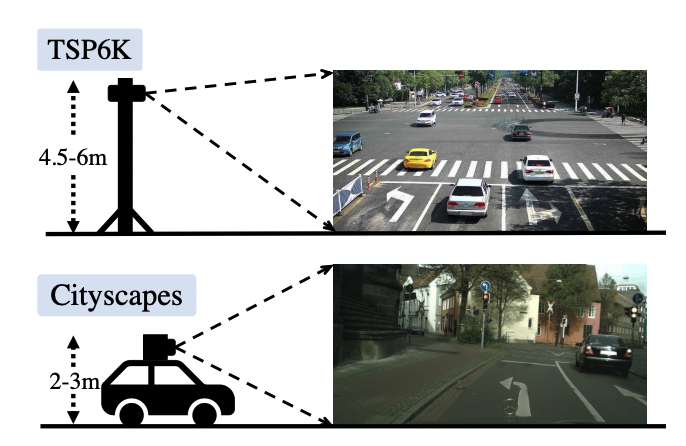 |
Peng-Tao Jiang*, Yuqi Yang*, Yang Cao, Qibin Hou, Ming-Ming Cheng, Chunhua Shen CVPR, 2024 paper /code /dataset[password:Wi9qFT] |
 |
Jiaxiong Qiu, Peng-Tao Jiang, Yifan Zhu, Ze-Xin Yin, Ming-Ming Cheng, Bo Ren CVPR, 2023 paper /code |
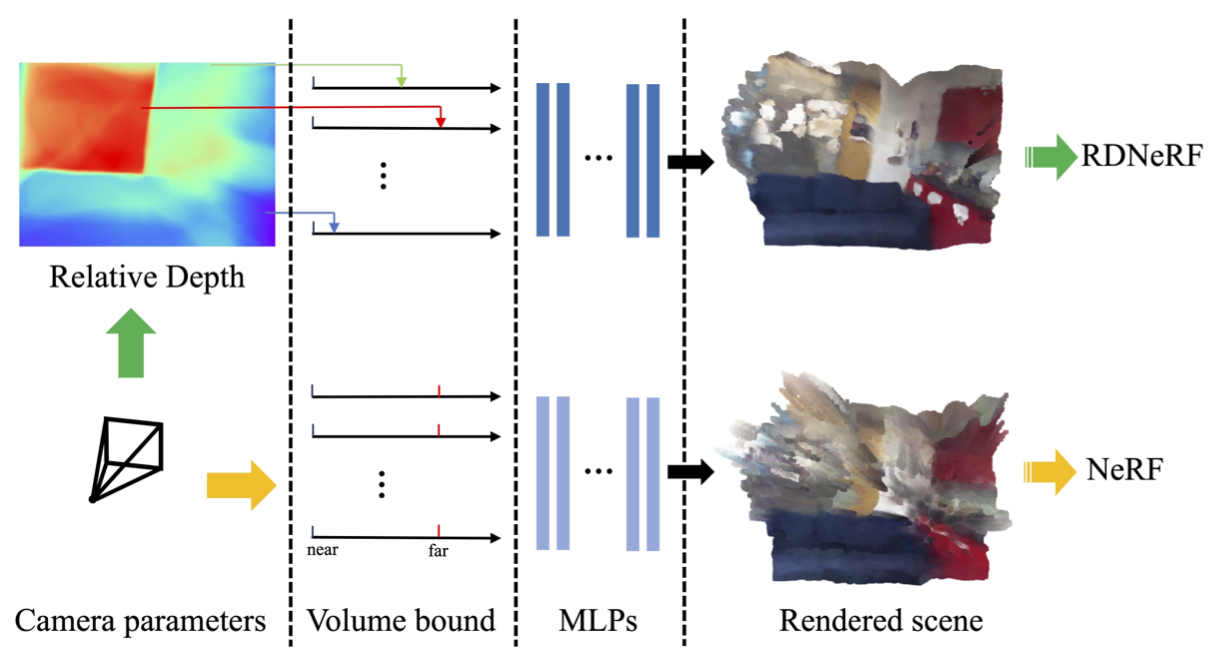 |
Jiaxiong Qiu*, Yifan Zhu*, Peng-Tao Jiang, Ming-Ming Cheng, Bo Ren TVC, 2023 paper /code |
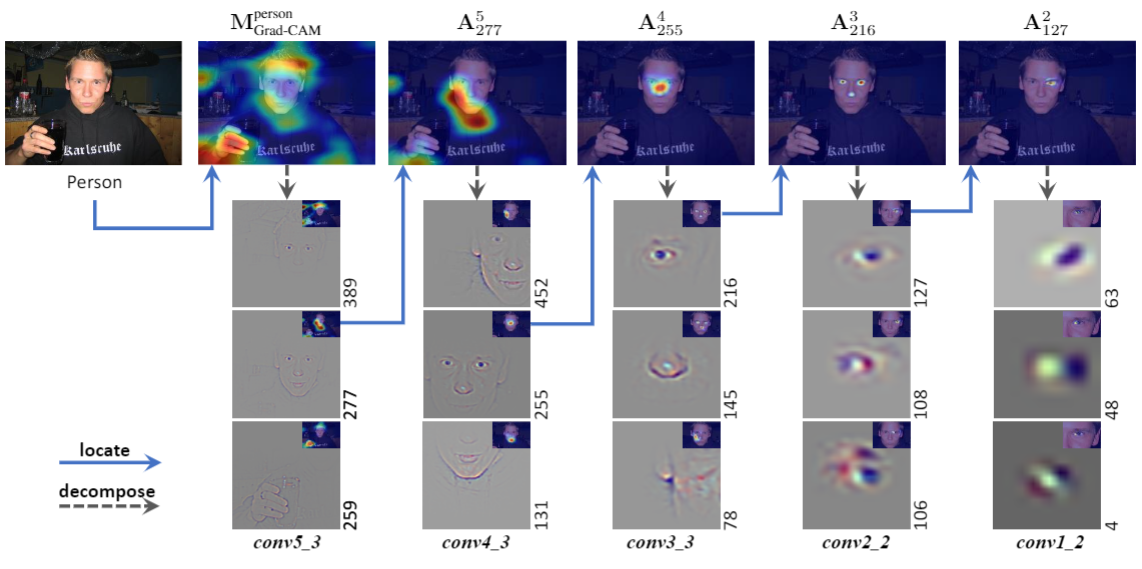 |
Ming-Ming Cheng*, Peng-Tao Jiang*, Ling-Hao Han, Liang Wang, Philip Torr IJCV, 2023 paper /demo |
|
|
Peng-Tao Jiang, Yuqi Yang, Qibin Hou, Yunchao Wei CVPR, 2022 paper /code |
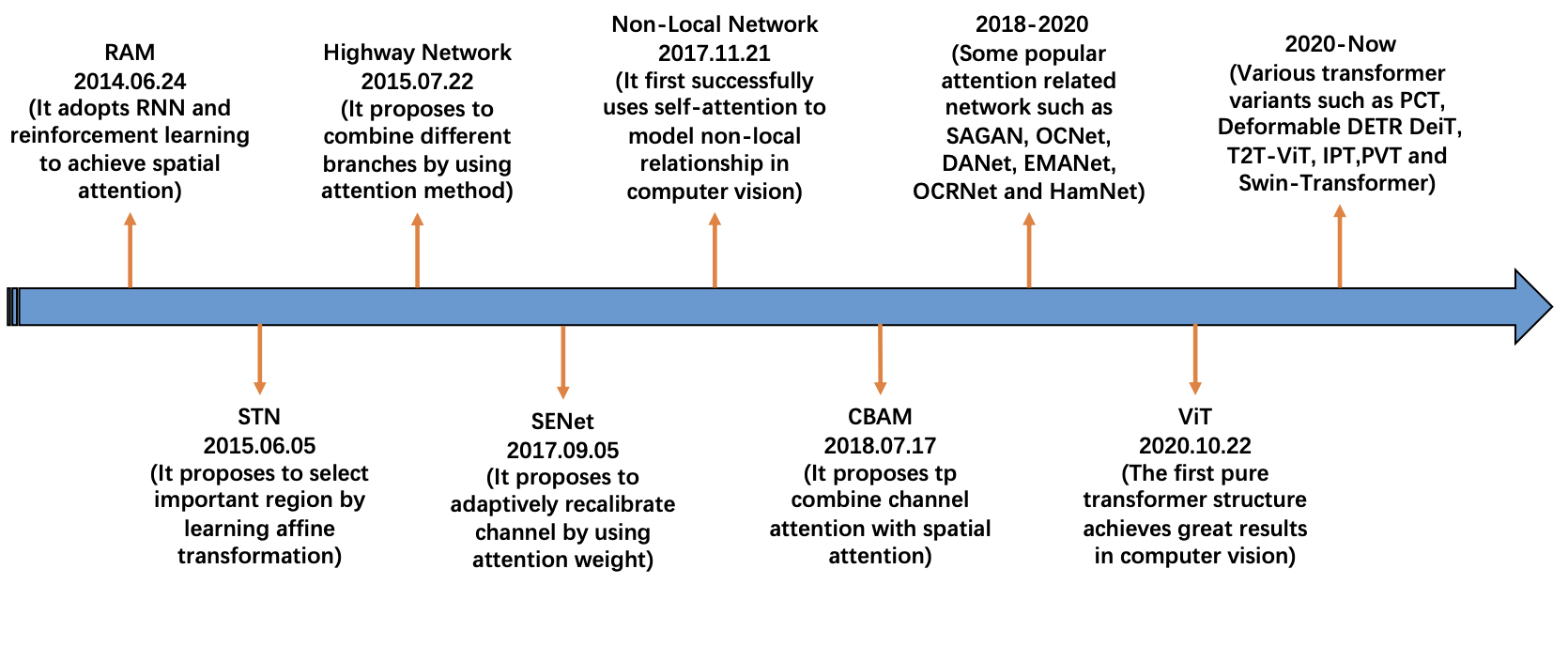 |
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R. Martin, Ming-Ming Cheng, and Shi-Min Hu CVMJ, 2022 paper /code /Best Paper Award |
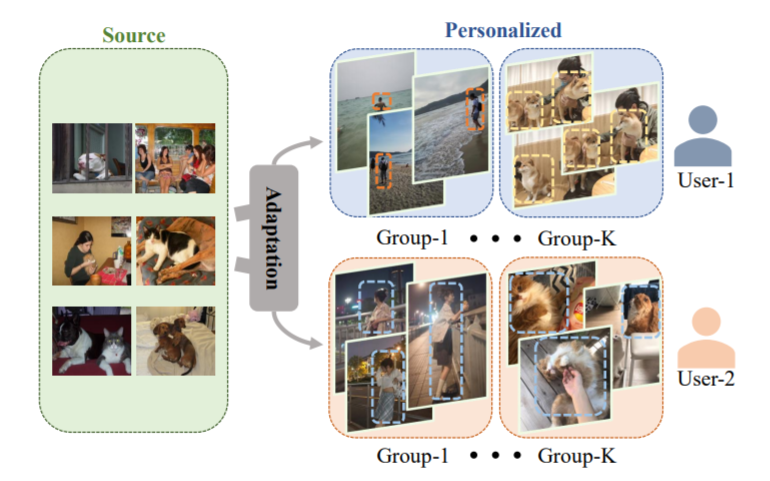 |
Yu Zhang, Chang-bin Zhang, Peng-Tao Jiang, Feng Mao, Ming-Ming Cheng ICCV, 2021 paper /code |
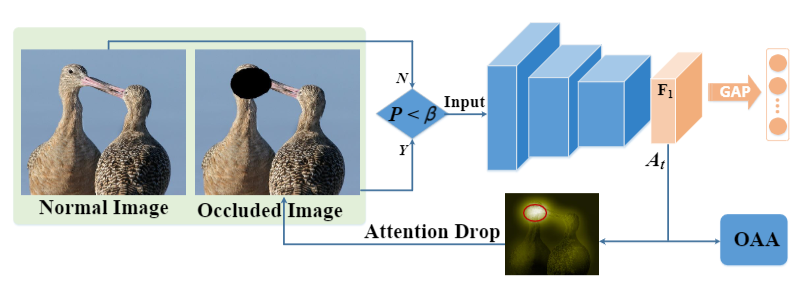 |
Peng-Tao Jiang*, Ling-Hao Han*, Qibin Hou, Ming-Ming Cheng, Yunchao Wei TPAMI, 2021 paper /code |
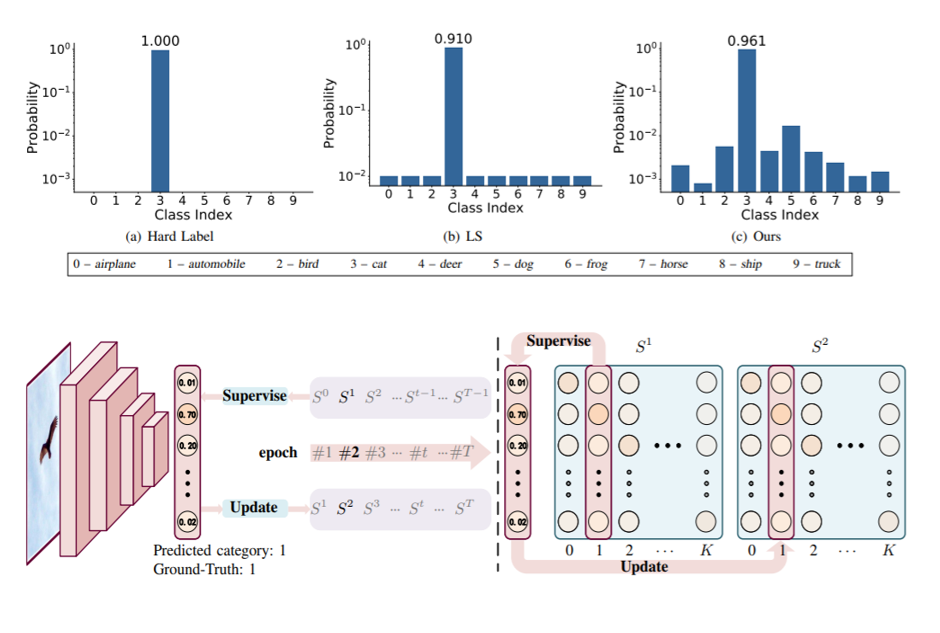 |
Chang-bin Zhang*, Peng-Tao Jiang*, Qibin Hou, Yunchao Wei, Qi Han, Zhen Li, Ming-Ming Cheng TIP, 2021 paper /code |
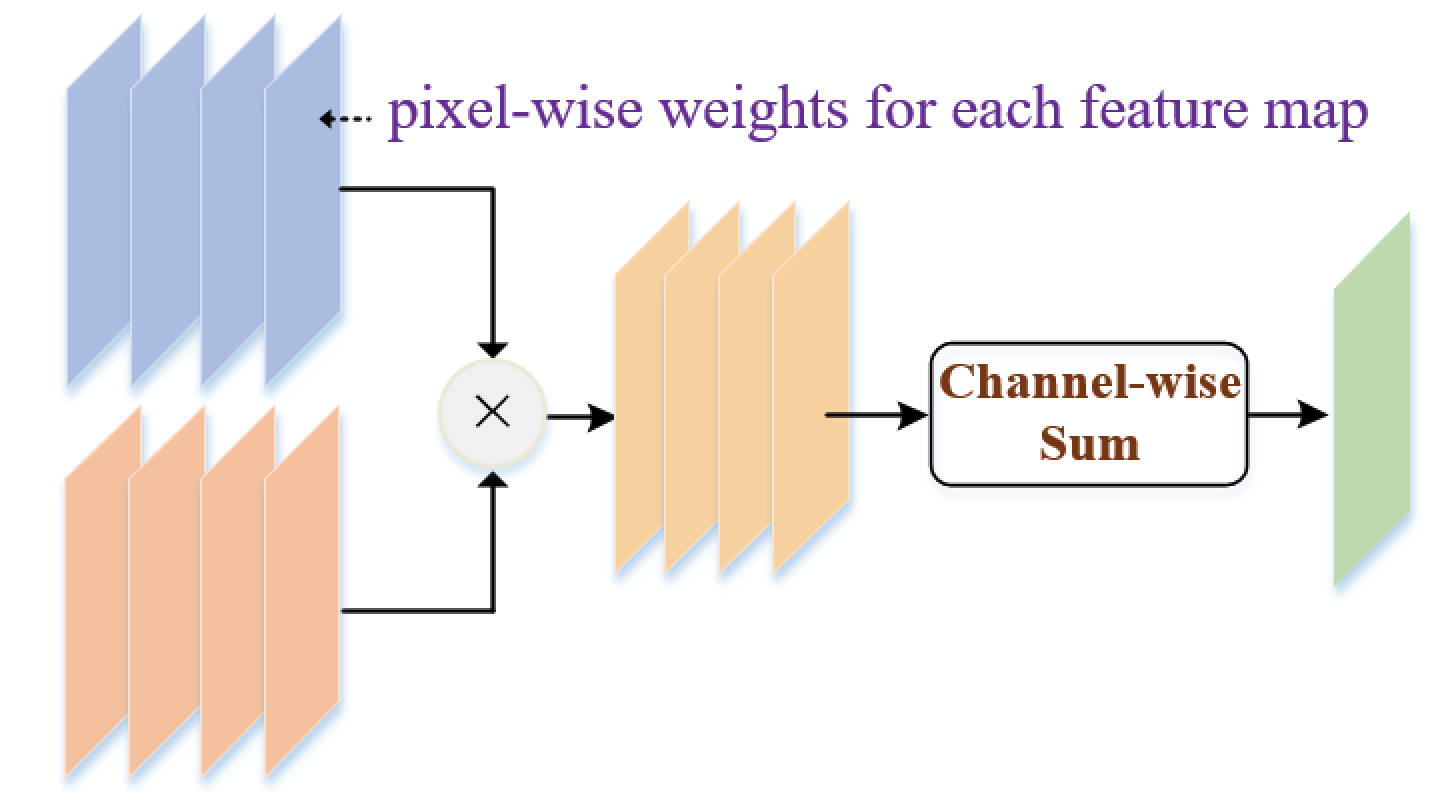 |
Peng-Tao Jiang*, Chang-bin Zhang*, Qibin Hou, Ming-Ming Cheng, Yunchao Wei TIP, 2021 paper /code |
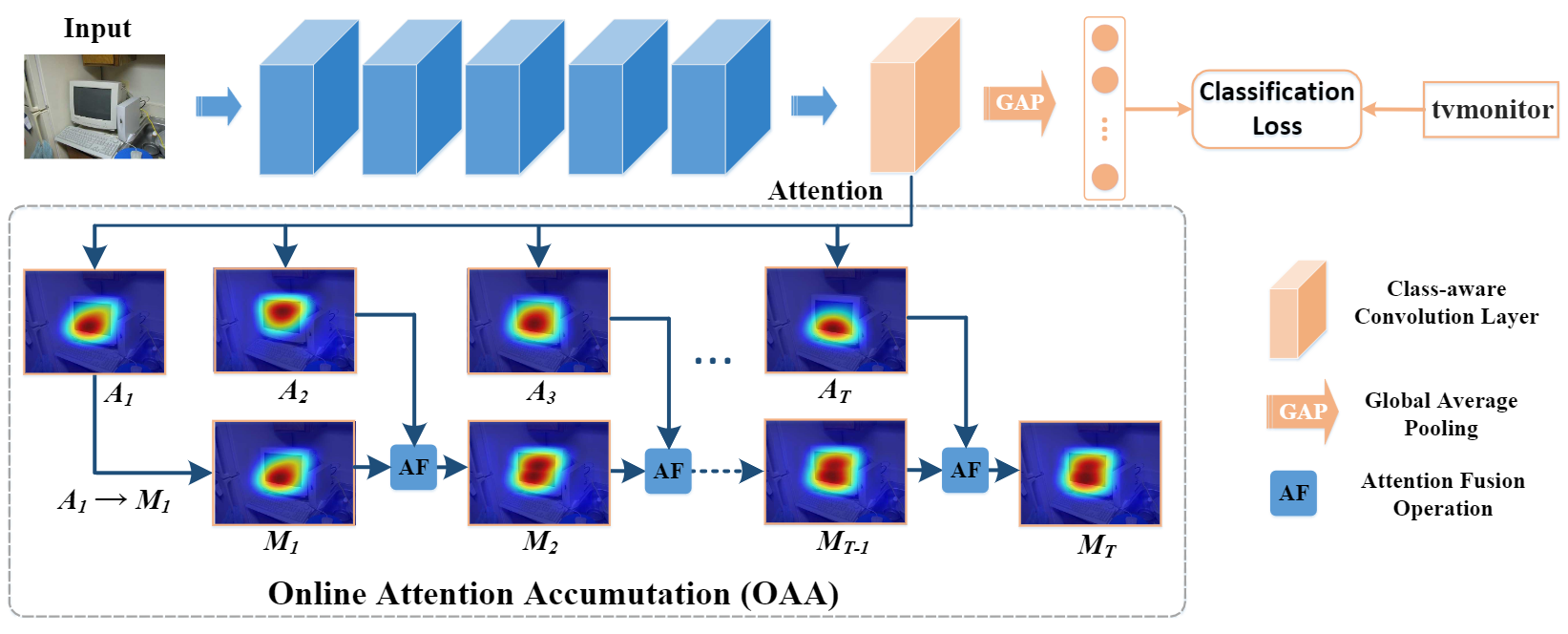 |
Peng-Tao Jiang, Qibin Hou, Yang Cao, Ming-Ming Cheng, Yunchao Wei, Hongkai Xiong ICCV, 2019 paper /code /project |
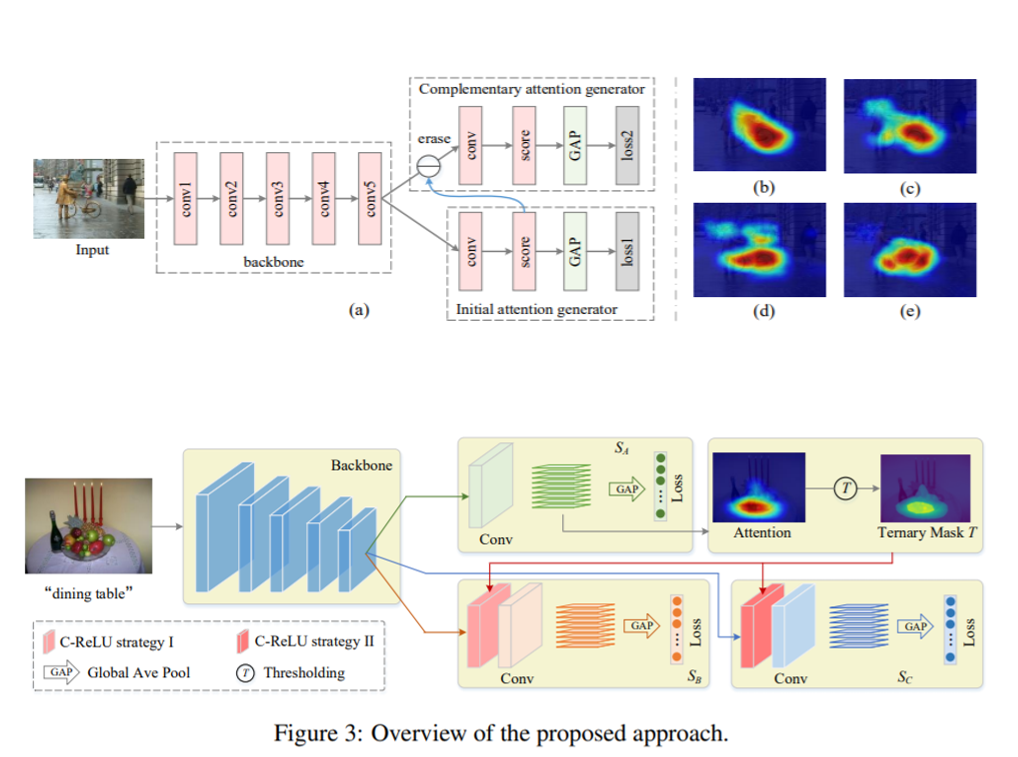 |
Qibin Hou, Peng-Tao Jiang, Yunchao Wei, Ming-Ming Cheng NeurIPS, 2018 paper /code |
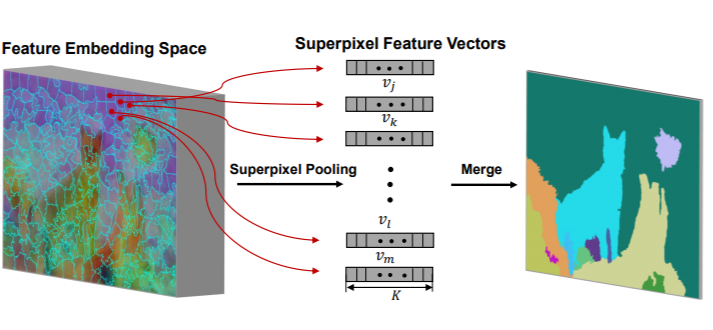 |
Yun Liu, Peng-Tao Jiang, Vahan Petrosyan, Shi-Jie Li, Jiawang Bian, Le Zhang, and Ming-Ming Cheng IJCAI, 2018 paper /code |
|
|
|
|
|
|
|
Thanks for the source codes from Yang Cao, Jon Barron |